
Problèmes d'encodage dans une application web
Il n’y a pas de solution miracle lorsqu’on a un problème d’encodage avec son application web. Mais avec un peu de méthode et quelques pistes, on peut en retrouver la/les sources(s) et les corriger.
Pour bien comprendre
Tous les développeurs devraient lire au moins une fois ces articles:
- les chaînes de caractères et l’encodage (les paragraphes 4.1 et 4.2 suffisent)
- Unicode
Avec ces articles vous comprendrez (entre autres!) pourquoi vous rencontrez ce problème, pourquoi il faut toujours connaître l’encodage d’un texte et pourquoi l’UTF-8 vous sauvra.
Vous le savez maintenant, détecter l’encodage d’un texte est une histoire de statistiques. Les outils suivants ne peuvent souvent que deviner l’encodage d’un texte qu’on leur donne:
file -i file.txt: un outil unix se basant sur les headers de fichierenca: aussi un outil unix, mais celui-ci se base sur le contenu du fichier- chardet, outil python qui se base aussi sur le contenu
Même chose pour vos éditeurs texte et navigateurs préférés: souvent, ils essaient seulement de deviner l’encodage ou bien font du “best effort”.
Les outils indispensables
Pour toutes les questions d’encodage, oubliez vos éditeurs de texte favoris et ne faites confiance qu’aux outils suivants:
- éditeurs hexa, comme vim: il est de base sur toutes les machines UNIX et devrait être sur votre poste de travail windows!
- des traffic dumpers, comme TCPdump
- des “strings témoins” (chaînes de caractères avec différents accents, pour tester chaque étape)
Astuce pour l’édition Hexa dans vim:
gvim -b myfile.txt
:%!xxd (pour voir la version en Hexa)
:%!xxd -r (pour reconvertir depuis l'Hexa)
Régler les problèmes d’encodage
Plan d’ensemble
Voici une architecture “classique” d’une application web Java. Dans la suite de l’article, nous allons suivre les maillons de cette chaîne pour trouver les problèmes d’encodage.
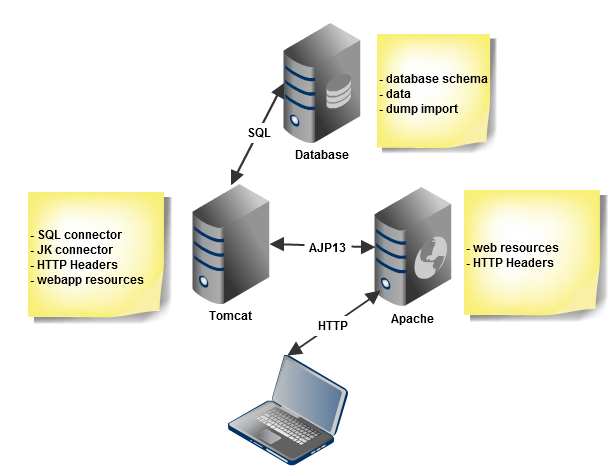
Encodage côté base de données
D’abord, vérifier que votre schéma/vos tables utilisent bien le charset UTF-8:
SELECT default_character_set_name FROM information_schema.SCHEMATA S
WHERE schema_name = 'your_schema_name'
use your_schema_name;
SHOW TABLE STATUS;
En cas de problème, supprimer et recréer votre schema avec un script SQL (ou votre ORM):
drop table if exists mydatabase_table;
create table mydatabase_table ( [...] )
engine=innodb default charset=utf8 collate=utf8_unicode_ci;
Attention, ne pas oublier d’indiquer le charset par défaut dans la ligne de commande:
mysql --default-character-set=utf8 myutf8_db < mydatabase.sql
Si votre base de données a le bon encodage, mais contient des données mal encodées, alors référez vous aux rubriques suivantes.
Connecteur SQL
Cette option n’est pas obligatoire, mais pourrait être la source d’un problème d’encodage; il faut alors vérifier la syntaxe de l’URL de connexion à la base de données:
connection.jdbc.url = jdbc:mysql://database.pullrequest.org:3306/your_schema_name?autoReconnect=true&useUnicode=true&characterEncoding=UTF-8
Connecteur JK
Si vous utilisez un connecteur JK entre Apache et Tomcat, des URLs mal encodées peuvent poser problème. Il faut alors modifier la configuration du connecteur pour bien encoder les caractères non-ASCII dans les URLs:
<connector enablelookups="false" port="10108" protocol="AJP/1.3" redirectport="8443" uriencoding="UTF-8">
Headers HTTP client
Parfois, les clients web n’envoient pas les bons Headers HTTP indiquant l’encoding des requêtes. C’est une source de données utilisateurs mal encodées en base de données; l’utilisation d’un encoding filter doit résoudre le problème.
<filter>
<filter-name>charsetEncodingFilter</filter-name>
<filter-class>org.springframework.web.filter.CharacterEncodingFilter</filter-class>
<init-param>
<param-name>encoding</param-name>
<param-value>UTF-8</param-value>
</init-param>
</filter>
<filter-mapping>
<filter-name>charsetEncodingFilter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
Les headers HTTP serveur
Il faut alors vérifier les Headers des réponses envoyées par les
différents serveurs de l’application: Tomcat, Apache/Nginx, etc.
Pas d’autre solution, il faut requêter ressources statiques (JS), APIs
serveur, page HTML et vérifier le header Content-type.
Les headers HTTP peuvent être écrits par:
- l’application web elle-même
- les modules apache
- le conteneur d’application Java
Les balises HTML
Toutes vos pages HTML doivent spécifier un encoding! En HTML5:
<!doctype html>
<head>
<meta charset="utf-8">
Les fichiers contenant des labels
Même si votre IDE ou votre éditeur texte indique un encoding UTF-8, il ne faut pas trop lui faire confiance.
Utiliser une string de test et vérifier en Hexa:
“Iñtërnâtiônàlizætiøn”
E2 80 9C 49 C3 B1 74 C3 AB 72 6E C3 A2 74 69 C3 B4 6E C3 A0 6C 69 7A C3 A6 74 69 C3 B8 6E E2 80 9D
Autres conseils avec: How to use UTF-8 troughout your web stack